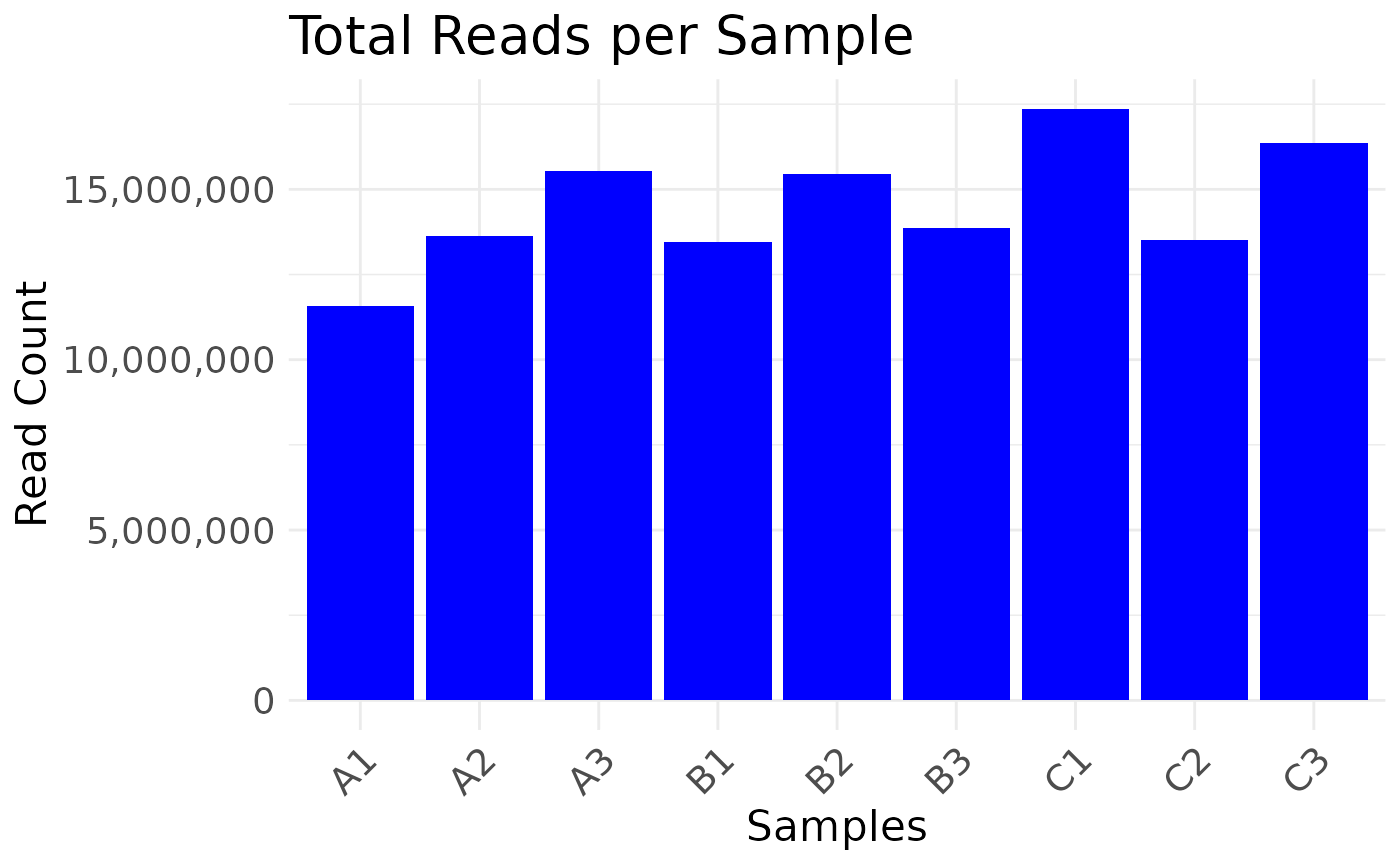
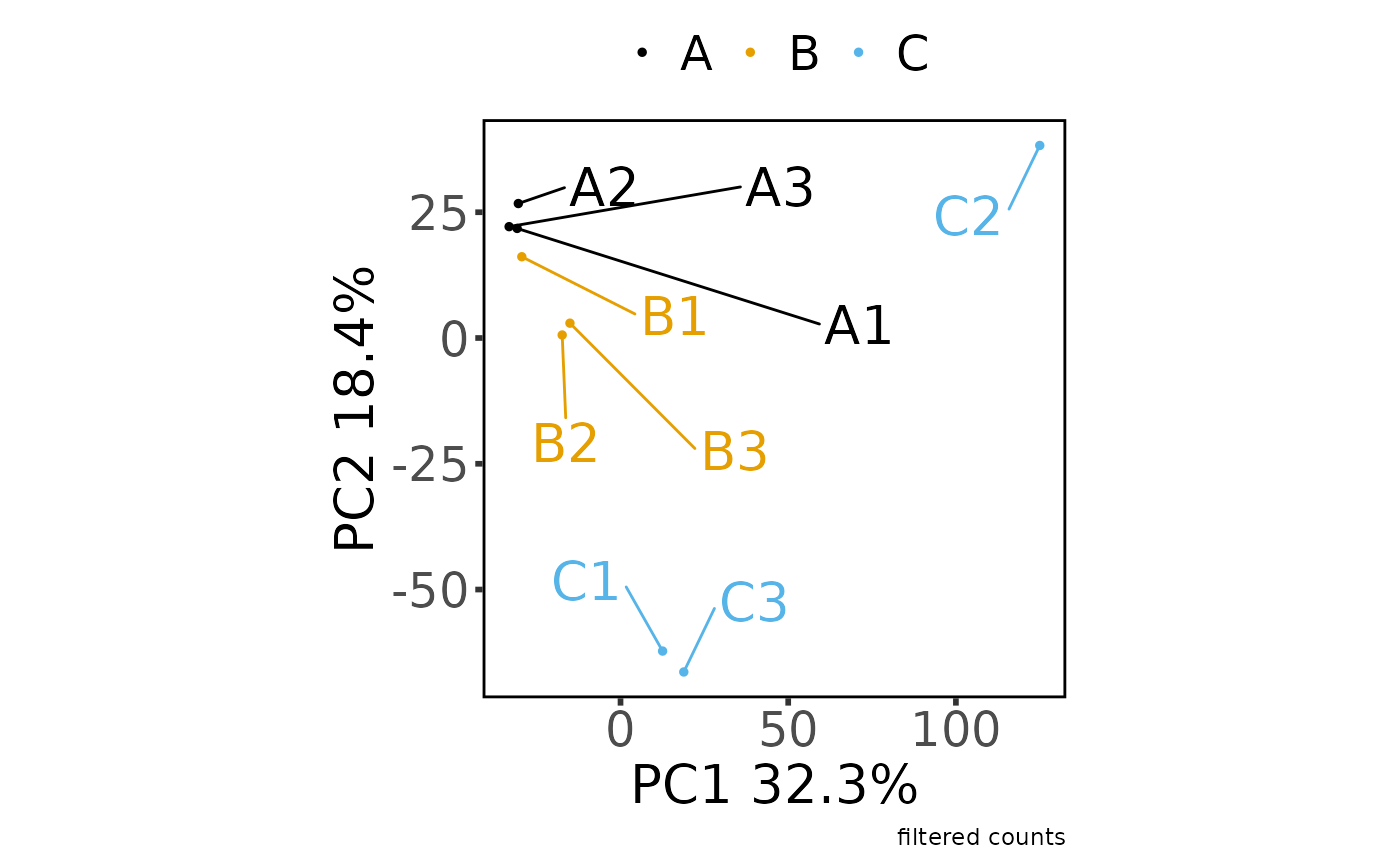
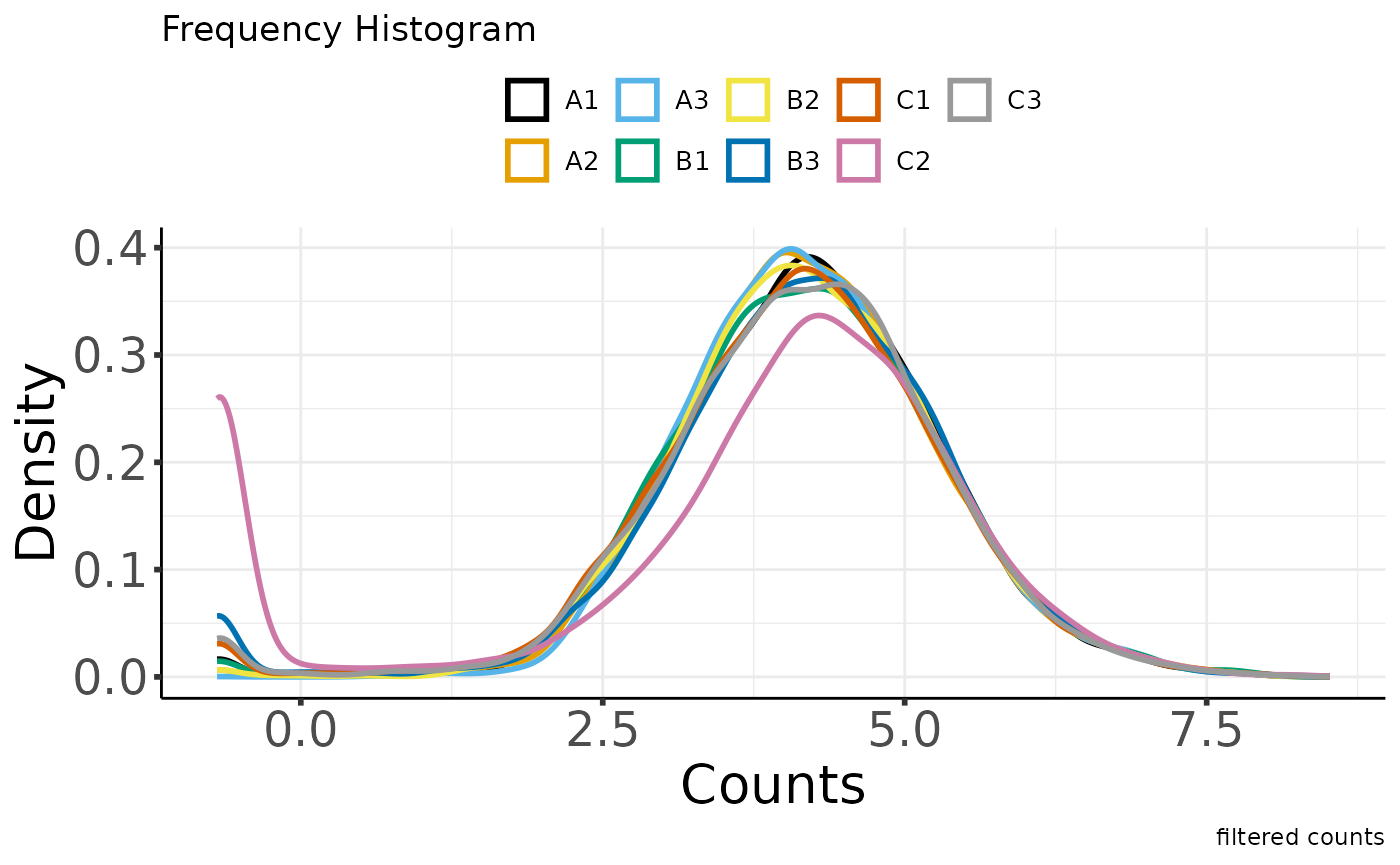
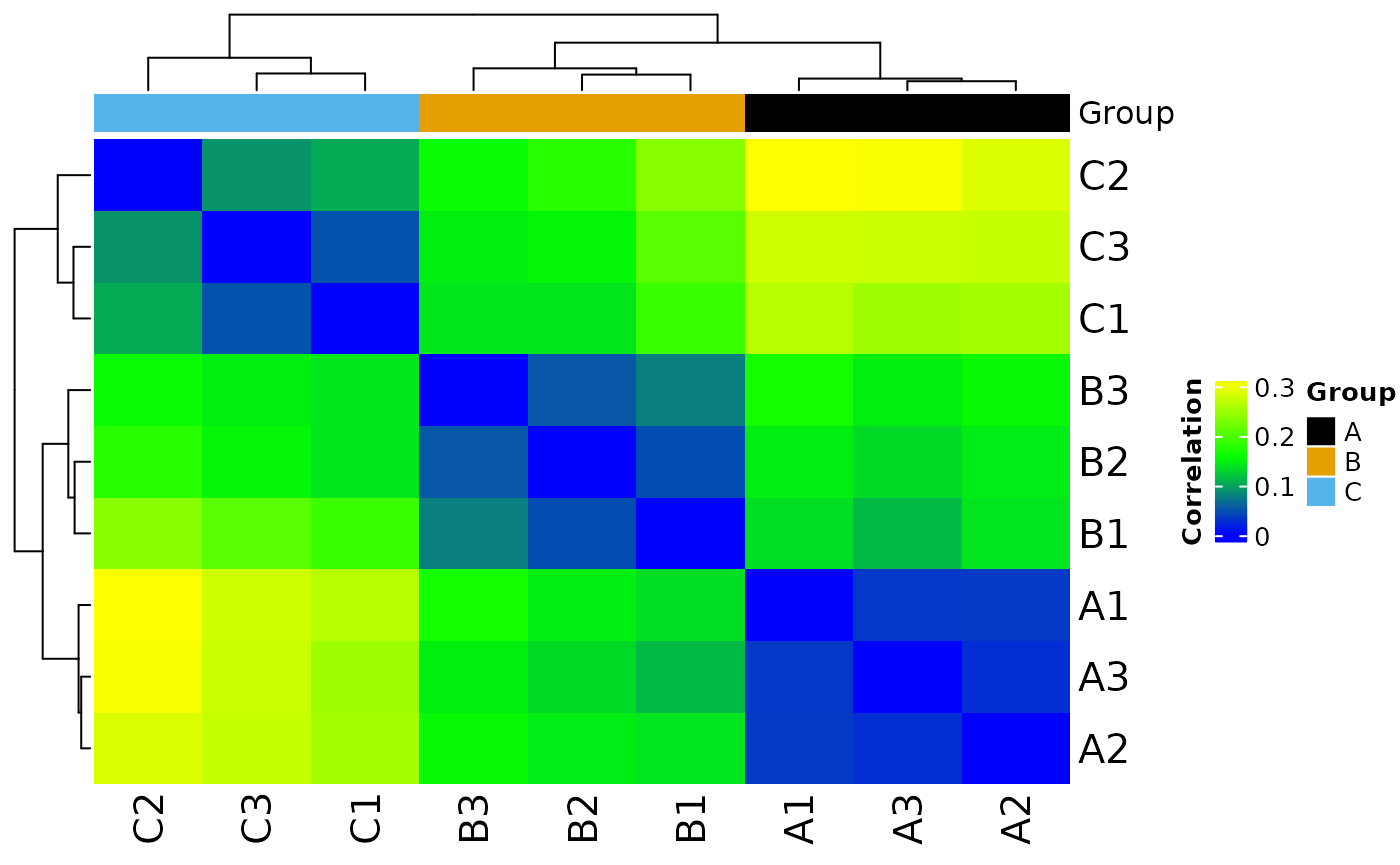
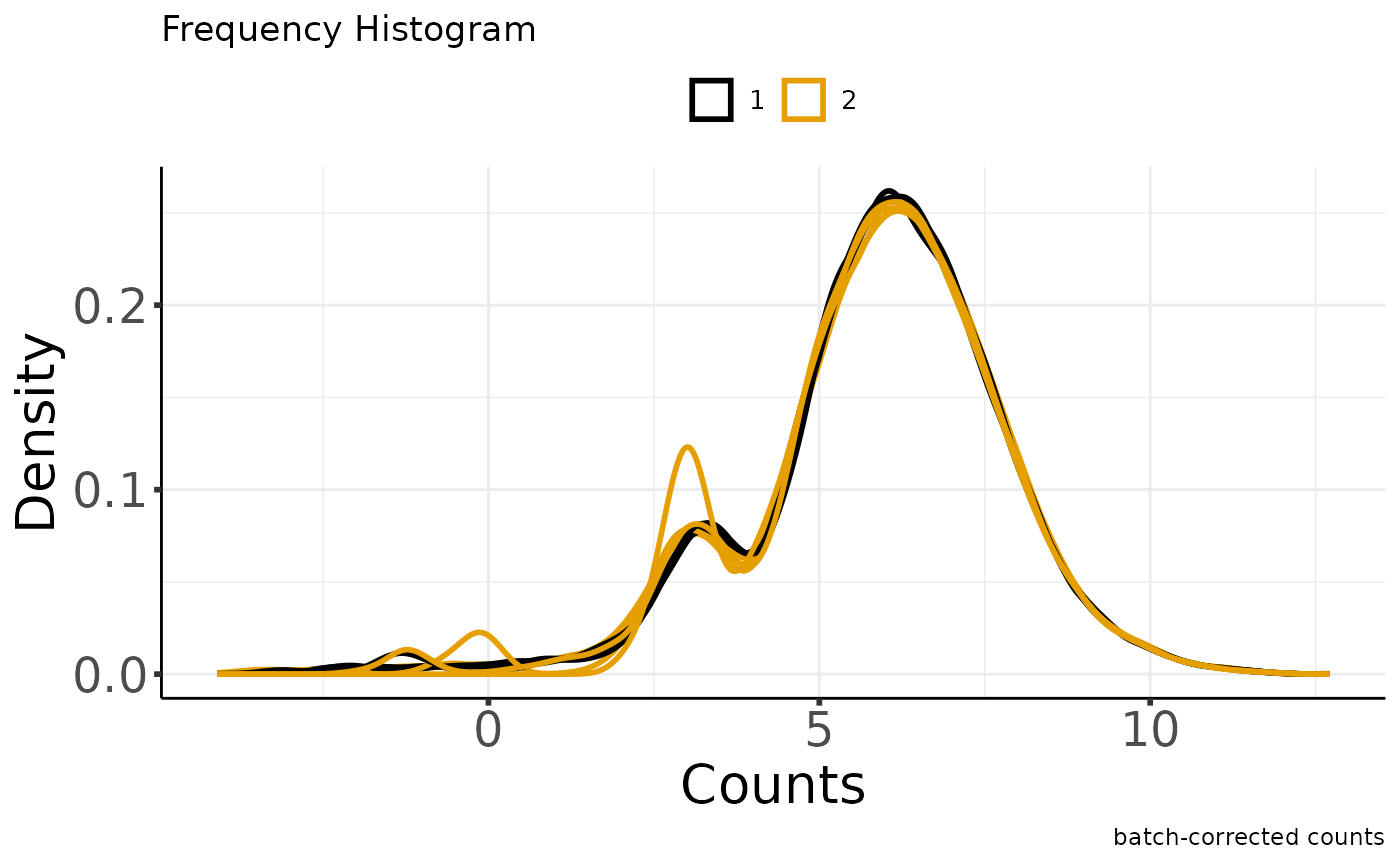
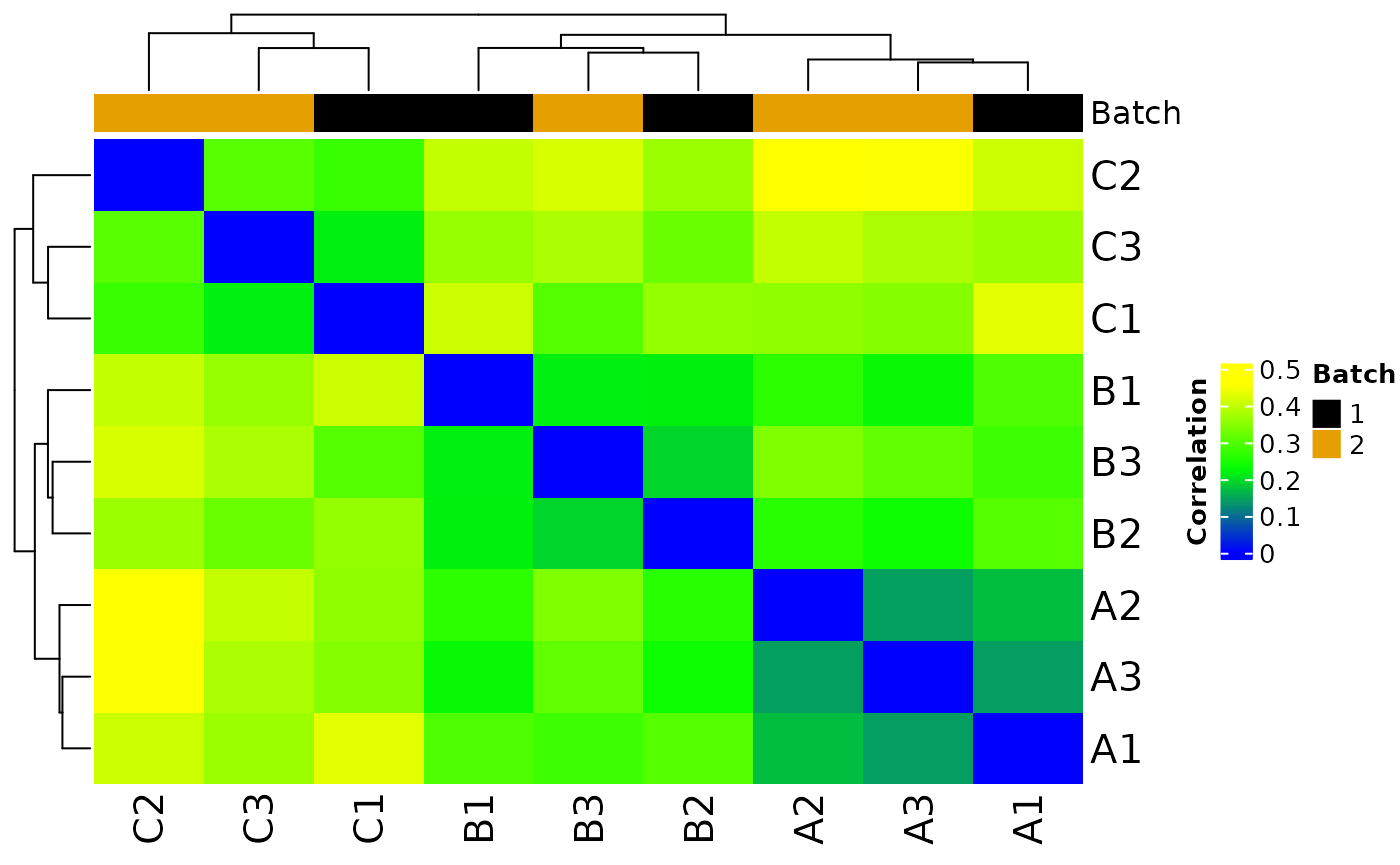
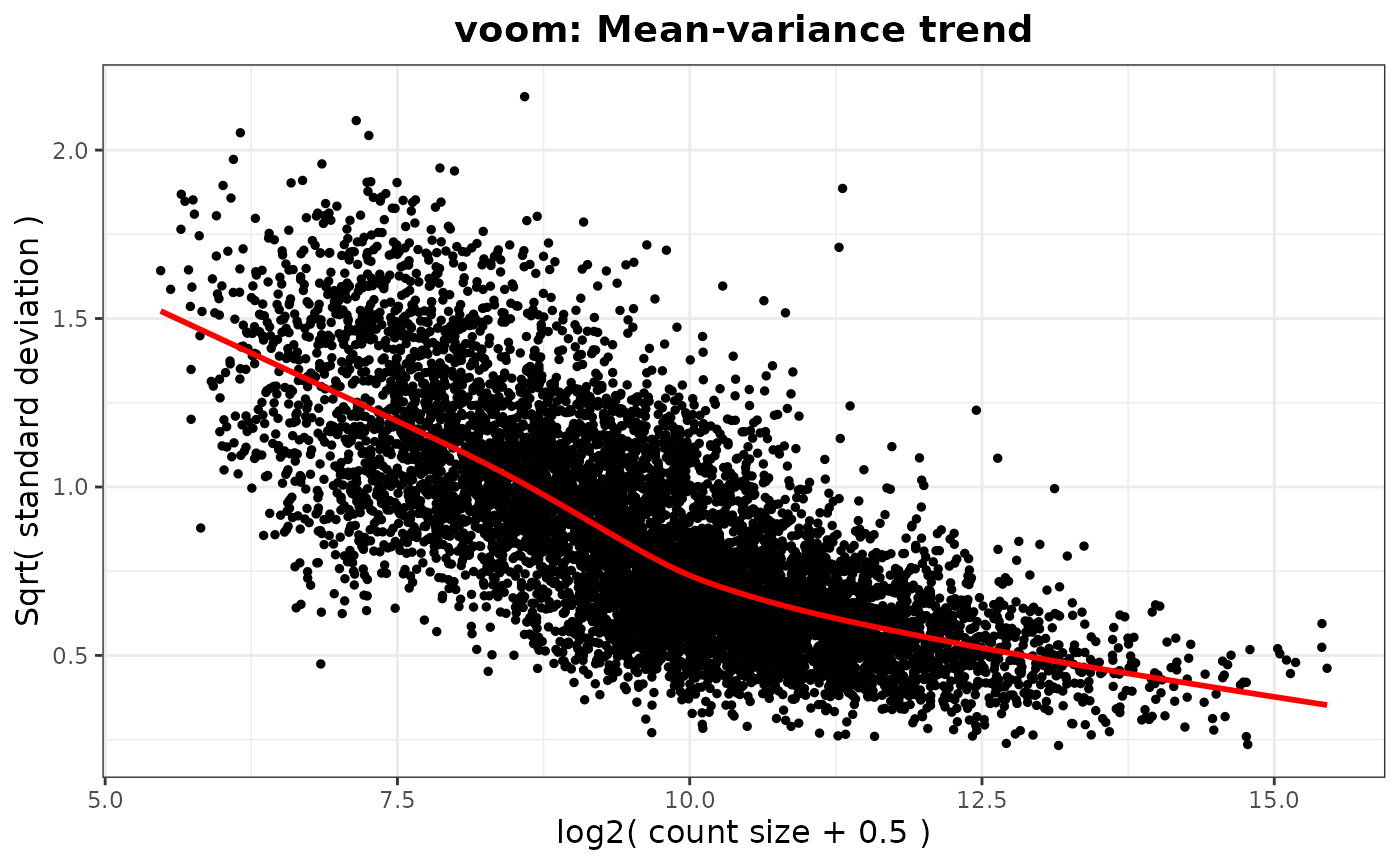
str(moo_nidap)
#> <MOSuite::multiOmicDataSet>
#> @ sample_meta:'data.frame': 9 obs. of 5 variables:
#> .. $ Sample : chr "A1" "A2" "A3" "B1" ...
#> .. $ Group : chr "A" "A" "A" "B" ...
#> .. $ Replicate: num 1 2 3 1 2 3 1 2 3
#> .. $ Batch : num 1 2 2 1 1 2 1 2 2
#> .. $ Label : chr "A1" "A2" "A3" "B1" ...
#> .. - attr(*, "spec")=List of 3
#> .. ..$ cols :List of 5
#> .. .. ..$ Sample : list()
#> .. .. .. ..- attr(*, "class")= chr [1:2] "collector_character" "collector"
#> .. .. ..$ Group : list()
#> .. .. .. ..- attr(*, "class")= chr [1:2] "collector_character" "collector"
#> .. .. ..$ Replicate: list()
#> .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. ..$ Batch : list()
#> .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. ..$ Label : list()
#> .. .. .. ..- attr(*, "class")= chr [1:2] "collector_character" "collector"
#> .. ..$ default: list()
#> .. .. ..- attr(*, "class")= chr [1:2] "collector_guess" "collector"
#> .. ..$ delim : chr ","
#> .. ..- attr(*, "class")= chr "col_spec"
#> .. - attr(*, "problems")=<externalptr>
#> @ annotation :'data.frame': 43280 obs. of 1 variable:
#> .. $ GeneName: chr "RP23-271O17.1" "Gm26206" "Xkr4" "RP23-317L18.1" ...
#> .. - attr(*, "spec")=List of 3
#> .. ..$ cols :List of 10
#> .. .. ..$ GeneName: list()
#> .. .. .. ..- attr(*, "class")= chr [1:2] "collector_character" "collector"
#> .. .. ..$ A1 : list()
#> .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. ..$ A2 : list()
#> .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. ..$ A3 : list()
#> .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. ..$ B1 : list()
#> .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. ..$ B2 : list()
#> .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. ..$ B3 : list()
#> .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. ..$ C1 : list()
#> .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. ..$ C2 : list()
#> .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. ..$ C3 : list()
#> .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. ..$ default: list()
#> .. .. ..- attr(*, "class")= chr [1:2] "collector_guess" "collector"
#> .. ..$ delim : chr ","
#> .. ..- attr(*, "class")= chr "col_spec"
#> .. - attr(*, "problems")=<externalptr>
#> @ counts :List of 5
#> .. $ raw :'data.frame': 43280 obs. of 10 variables:
#> .. ..$ GeneName: chr [1:43280] "RP23-271O17.1" "Gm26206" "Xkr4" "RP23-317L18.1" ...
#> .. ..$ A1 : num [1:43280] 0 0 0 0 0 0 0 0 0 0 ...
#> .. ..$ A2 : num [1:43280] 0 0 0 0 0 0 0 0 0 0 ...
#> .. ..$ A3 : num [1:43280] 0 0 0 0 0 0 0 0 0 0 ...
#> .. ..$ B1 : num [1:43280] 0 0 0 0 0 0 0 0 0 0 ...
#> .. ..$ B2 : num [1:43280] 0 0 0 0 0 0 0 0 0 1 ...
#> .. ..$ B3 : num [1:43280] 0 0 0 0 0 0 0 0 0 0 ...
#> .. ..$ C1 : num [1:43280] 0 0 0 0 0 0 0 0 0 0 ...
#> .. ..$ C2 : num [1:43280] 0 0 0 0 0 0 0 0 0 0 ...
#> .. ..$ C3 : num [1:43280] 0 0 0 0 0 0 0 0 0 0 ...
#> .. ..- attr(*, "spec")=List of 3
#> .. .. ..$ cols :List of 10
#> .. .. .. ..$ GeneName: list()
#> .. .. .. .. ..- attr(*, "class")= chr [1:2] "collector_character" "collector"
#> .. .. .. ..$ A1 : list()
#> .. .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. .. ..$ A2 : list()
#> .. .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. .. ..$ A3 : list()
#> .. .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. .. ..$ B1 : list()
#> .. .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. .. ..$ B2 : list()
#> .. .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. .. ..$ B3 : list()
#> .. .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. .. ..$ C1 : list()
#> .. .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. .. ..$ C2 : list()
#> .. .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. .. ..$ C3 : list()
#> .. .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. ..$ default: list()
#> .. .. .. ..- attr(*, "class")= chr [1:2] "collector_guess" "collector"
#> .. .. ..$ delim : chr ","
#> .. .. ..- attr(*, "class")= chr "col_spec"
#> .. ..- attr(*, "problems")=<externalptr>
#> .. $ clean:'data.frame': 43280 obs. of 10 variables:
#> .. ..$ GeneName: chr [1:43280] "RP23-271O17.1" "Gm26206" "Xkr4" "RP23-317L18.1" ...
#> .. ..$ A1 : num [1:43280] 0 0 0 0 0 0 0 0 0 0 ...
#> .. ..$ A2 : num [1:43280] 0 0 0 0 0 0 0 0 0 0 ...
#> .. ..$ A3 : num [1:43280] 0 0 0 0 0 0 0 0 0 0 ...
#> .. ..$ B1 : num [1:43280] 0 0 0 0 0 0 0 0 0 0 ...
#> .. ..$ B2 : num [1:43280] 0 0 0 0 0 0 0 0 0 1 ...
#> .. ..$ B3 : num [1:43280] 0 0 0 0 0 0 0 0 0 0 ...
#> .. ..$ C1 : num [1:43280] 0 0 0 0 0 0 0 0 0 0 ...
#> .. ..$ C2 : num [1:43280] 0 0 0 0 0 0 0 0 0 0 ...
#> .. ..$ C3 : num [1:43280] 0 0 0 0 0 0 0 0 0 0 ...
#> .. ..- attr(*, "spec")=List of 3
#> .. .. ..$ cols :List of 10
#> .. .. .. ..$ GeneName: list()
#> .. .. .. .. ..- attr(*, "class")= chr [1:2] "collector_character" "collector"
#> .. .. .. ..$ A1 : list()
#> .. .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. .. ..$ A2 : list()
#> .. .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. .. ..$ A3 : list()
#> .. .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. .. ..$ B1 : list()
#> .. .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. .. ..$ B2 : list()
#> .. .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. .. ..$ B3 : list()
#> .. .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. .. ..$ C1 : list()
#> .. .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. .. ..$ C2 : list()
#> .. .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. .. ..$ C3 : list()
#> .. .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. ..$ default: list()
#> .. .. .. ..- attr(*, "class")= chr [1:2] "collector_guess" "collector"
#> .. .. ..$ delim : chr ","
#> .. .. ..- attr(*, "class")= chr "col_spec"
#> .. ..- attr(*, "problems")=<externalptr>
#> .. $ filt :'data.frame': 7943 obs. of 10 variables:
#> .. ..$ GeneName: chr [1:7943] "Mrpl15" "Lypla1" "Tcea1" "Atp6v1h" ...
#> .. ..$ A1 : num [1:7943] 1245 1483 1381 1033 666 ...
#> .. ..$ A2 : num [1:7943] 1341 1410 2044 1959 1397 ...
#> .. ..$ A3 : num [1:7943] 1476 1370 2051 1890 1576 ...
#> .. ..$ B1 : num [1:7943] 965 1146 2325 2075 681 ...
#> .. ..$ B2 : num [1:7943] 1235 1422 2386 2702 2040 ...
#> .. ..$ B3 : num [1:7943] 1784 2624 1893 2150 1988 ...
#> .. ..$ C1 : num [1:7943] 1058 991 2391 2436 774 ...
#> .. ..$ C2 : num [1:7943] 1732 1101 916 1321 1921 ...
#> .. ..$ C3 : num [1:7943] 1531 2352 2261 1018 2660 ...
#> .. ..- attr(*, "spec")=List of 3
#> .. .. ..$ cols :List of 10
#> .. .. .. ..$ GeneName: list()
#> .. .. .. .. ..- attr(*, "class")= chr [1:2] "collector_character" "collector"
#> .. .. .. ..$ A1 : list()
#> .. .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. .. ..$ A2 : list()
#> .. .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. .. ..$ A3 : list()
#> .. .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. .. ..$ B1 : list()
#> .. .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. .. ..$ B2 : list()
#> .. .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. .. ..$ B3 : list()
#> .. .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. .. ..$ C1 : list()
#> .. .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. .. ..$ C2 : list()
#> .. .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. .. ..$ C3 : list()
#> .. .. .. .. ..- attr(*, "class")= chr [1:2] "collector_double" "collector"
#> .. .. ..$ default: list()
#> .. .. .. ..- attr(*, "class")= chr [1:2] "collector_guess" "collector"
#> .. .. ..$ delim : chr ","
#> .. .. ..- attr(*, "class")= chr "col_spec"
#> .. ..- attr(*, "problems")=<externalptr>
#> .. $ norm :List of 1
#> .. ..$ voom:'data.frame': 7943 obs. of 10 variables:
#> .. .. ..$ GeneName: chr [1:7943] "Mrpl15" "Lypla1" "Tcea1" "Atp6v1h" ...
#> .. .. ..$ A1 : num [1:7943] 6.79 7.04 6.93 6.51 5.85 ...
#> .. .. ..$ A2 : num [1:7943] 6.7 6.78 7.32 7.26 6.76 ...
#> .. .. ..$ A3 : num [1:7943] 6.64 6.53 7.13 7 6.75 ...
#> .. .. ..$ B1 : num [1:7943] 6.22 6.47 7.48 7.31 5.75 ...
#> .. .. ..$ B2 : num [1:7943] 6.38 6.57 7.33 7.52 7.11 ...
#> .. .. ..$ B3 : num [1:7943] 7.02 7.59 7.11 7.3 7.17 ...
#> .. .. ..$ C1 : num [1:7943] 6.02 5.92 7.19 7.22 5.56 ...
#> .. .. ..$ C2 : num [1:7943] 7.03 6.43 6.19 6.67 7.19 ...
#> .. .. ..$ C3 : num [1:7943] 6.6 7.25 7.2 6.01 7.43 ...
#> .. $ batch:'data.frame': 7943 obs. of 10 variables:
#> .. ..$ GeneName: chr [1:7943] "Mrpl15" "Lypla1" "Tcea1" "Atp6v1h" ...
#> .. ..$ A1 : num [1:7943] 6.92 7.2 6.87 6.51 6.23 ...
#> .. ..$ A2 : num [1:7943] 6.59 6.66 7.33 7.25 6.46 ...
#> .. ..$ A3 : num [1:7943] 6.54 6.43 7.16 7.02 6.45 ...
#> .. ..$ B1 : num [1:7943] 6.41 6.68 7.42 7.28 6.27 ...
#> .. ..$ B2 : num [1:7943] 6.55 6.78 7.27 7.47 7.35 ...
#> .. ..$ B3 : num [1:7943] 6.88 7.4 7.16 7.33 6.89 ...
#> .. ..$ C1 : num [1:7943] 6.21 6.13 7.13 7.13 6.06 ...
#> .. ..$ C2 : num [1:7943] 6.87 6.32 6.32 6.69 6.88 ...
#> .. ..$ C3 : num [1:7943] 6.48 7.04 7.18 6.1 7.1 ...
#> @ analyses :List of 3
#> .. $ colors :List of 5
#> .. ..$ Sample : Named chr [1:9] "#000000" "#E69F00" "#56B4E9" "#009E73" ...
#> .. .. ..- attr(*, "names")= chr [1:9] "A1" "A2" "A3" "B1" ...
#> .. ..$ Group : Named chr [1:3] "#000000" "#E69F00" "#56B4E9"
#> .. .. ..- attr(*, "names")= chr [1:3] "A" "B" "C"
#> .. ..$ Replicate: Named chr [1:3] "#000000" "#E69F00" "#56B4E9"
#> .. .. ..- attr(*, "names")= chr [1:3] "1" "2" "3"
#> .. ..$ Batch : Named chr [1:2] "#000000" "#E69F00"
#> .. .. ..- attr(*, "names")= chr [1:2] "1" "2"
#> .. ..$ Label : Named chr [1:9] "#000000" "#E69F00" "#56B4E9" "#009E73" ...
#> .. .. ..- attr(*, "names")= chr [1:9] "A1" "A2" "A3" "B1" ...
#> .. $ diff :List of 3
#> .. ..$ B-A:'data.frame': 7943 obs. of 6 variables:
#> .. .. ..$ GeneName: chr [1:7943] "Mrpl15" "Lypla1" "Tcea1" "Atp6v1h" ...
#> .. .. ..$ FC : num [1:7943] 1.06 1.37 1.08 1.31 1.52 ...
#> .. .. ..$ logFC : num [1:7943] 0.0799 0.4493 0.1157 0.3921 0.6014 ...
#> .. .. ..$ tstat : num [1:7943] 0.23 1.118 0.365 1.128 1.314 ...
#> .. .. ..$ pval : num [1:7943] 0.822 0.286 0.722 0.282 0.214 ...
#> .. .. ..$ adjpval : num [1:7943] 0.968 0.784 0.95 0.781 0.717 ...
#> .. ..$ C-A:'data.frame': 7943 obs. of 6 variables:
#> .. .. ..$ GeneName: chr [1:7943] "Mrpl15" "Lypla1" "Tcea1" "Atp6v1h" ...
#> .. .. ..$ FC : num [1:7943] -1.07 -1.07 -1.18 -1.22 1.31 ...
#> .. .. ..$ logFC : num [1:7943] -0.0979 -0.0999 -0.2365 -0.2884 0.3921 ...
#> .. .. ..$ tstat : num [1:7943] -0.297 -0.255 -0.764 -0.832 0.903 ...
#> .. .. ..$ pval : num [1:7943] 0.772 0.803 0.46 0.422 0.385 ...
#> .. .. ..$ adjpval : num [1:7943] 0.889 0.907 0.69 0.659 0.628 ...
#> .. ..$ B-C:'data.frame': 7943 obs. of 6 variables:
#> .. .. ..$ GeneName: chr [1:7943] "Mrpl15" "Lypla1" "Tcea1" "Atp6v1h" ...
#> .. .. ..$ FC : num [1:7943] 1.13 1.46 1.28 1.6 1.16 ...
#> .. .. ..$ logFC : num [1:7943] 0.178 0.549 0.352 0.681 0.209 ...
#> .. .. ..$ tstat : num [1:7943] 0.528 1.396 1.131 1.99 0.495 ...
#> .. .. ..$ pval : num [1:7943] 0.6077 0.1887 0.2806 0.0705 0.6296 ...
#> .. .. ..$ adjpval : num [1:7943] 0.836 0.486 0.588 0.316 0.847 ...
#> .. $ diff_filt:'data.frame': 641 obs. of 16 variables:
#> .. ..$ GeneName : chr [1:641] "Rrs1" "Mcm3" "Ogfrl1" "Smap1" ...
#> .. ..$ B-A_FC : num [1:641] -2.06 -1.45 1.07 2.96 -1.24 2.42 -1.63 2.4 53.3 1.63 ...
#> .. ..$ B-A_logFC : num [1:641] -1.04 -0.54 0.102 1.57 -0.312 1.28 -0.708 1.26 5.74 0.709 ...
#> .. ..$ B-A_tstat : num [1:641] -2.86 -1.85 0.293 2.01 -1.1 0.716 -1.9 3.2 3.65 1.93 ...
#> .. ..$ B-A_pval : num [1:641] 0.0146 0.0895 0.775 0.0686 0.295 0.488 0.0821 0.0079 0.00344 0.0786 ...
#> .. ..$ B-A_adjpval: num [1:641] 0.274 0.549 0.96 0.5 0.789 0.873 0.532 0.211 0.139 0.525 ...
#> .. ..$ C-A_FC : num [1:641] -2.71 -2.46 -3.77 5.68 2.69 36.6 3.13 2.74 287 -6.41 ...
#> .. ..$ C-A_logFC : num [1:641] -1.44 -1.3 -1.92 2.51 1.43 5.19 1.65 1.45 8.16 -2.68 ...
#> .. ..$ C-A_tstat : num [1:641] -3.84 -4.31 -4.03 3.59 5.98 3.16 5.61 3.97 5.45 -3.83 ...
#> .. ..$ C-A_pval : num [1:641] 2.45e-03 1.07e-03 1.74e-03 3.81e-03 7.03e-05 8.41e-03 1.25e-04 1.95e-03 1.60e-04 2.50e-03 ...
#> .. ..$ C-A_adjpval: num [1:641] 0.0364 0.0229 0.0305 0.0469 0.00461 0.0745 0.00655 0.0321 0.00759 0.0368 ...
#> .. ..$ B-C_FC : num [1:641] 1.32 1.69 4.05 -1.92 -3.34 -15.1 -5.11 -1.14 -5.38 10.5 ...
#> .. ..$ B-C_logFC : num [1:641] 0.4 0.756 2.02 -0.938 -1.74 -3.92 -2.35 -0.19 -2.43 3.39 ...
#> .. ..$ B-C_tstat : num [1:641] 0.945 2.36 4.01 -1.74 -6.97 -4.21 -7.09 -0.585 -4 4.57 ...
#> .. ..$ B-C_pval : num [1:641] 3.64e-01 3.62e-02 1.79e-03 1.07e-01 1.69e-05 1.26e-03 1.43e-05 5.69e-01 1.84e-03 6.86e-04 ...
#> .. ..$ B-C_adjpval: num [1:641] 0.664 0.234 0.0557 0.38 0.00334 0.0469 0.00307 0.815 0.0562 0.0334 ...